Topic – Machine Learning Algorithms for Beginners
What is Machine Learning? Uncovering the myth!
Machine learning (ML) is one of the hottest fields in computer science, which learns patterns from the data, and predicts future outcomes from it!
So many beginners are jumping with the fake idea that it’s just about running 7 lines of python code and expecting things to work by magic in any situation.
No! Machine Learning Algorithms is a lot, a hell of a lot of Math!

Thinking to step back?….Wait there!
Machine learning is like any scientific field: it has its own rules, logic, and of course, limitations.
Although it has a lot of math, you don’t certainly need to sit with pen paper and solve differential and multivariate calculus!
You must have a good backend knowledge on how mathematically the algorithm works, and yay!…there you go!
Which Machine Learning algorithm to study first? Why?
Anybody who is a beginner in Machine Learning, for at least once would cry over the fact that-
“Oh my god! There are so many machine learning algorithms!! What to do and what to leave?”
Don’t feel bad about this though, and just try to focus on smart work rather than hard work!
A lot of people jump into complex Machine Learning algorithms, without any idea of why they are studying it, or where they will apply. You must study the basics first, and then get on with the complex algorithms, as and when required!
In this article, I will introduce you to the 4 most important Machine Learning Algorithms for Beginners! After this blog, you can confidently learn any complex machine learning algorithm, even as a beginner!
So beginners, let’s dive into the Important Machine Learning Algorithms for Beginners
1. Logistic Regression – Simple and Smart!

Logistic regression is the most famous machine learning algorithm after linear regression. In a lot of ways, linear regression and logistic regression are similar. But, the biggest difference lies in what they are used for.
Linear regression algorithms are used to predict/forecast values, but logistic regression is used for classification tasks.
The logistic regression algorithm also uses a linear equation with independent predictors to predict a value. The predicted value can be anywhere between negative infinity to positive infinity.
We need the output of the algorithm to be a class variable, i.e. 0-no, 1-yes. Therefore, we are squashing the output of the linear equation into a range of [0,1]. To squash the predicted value between 0 and 1, we use the sigmoid function.
A simple implementation of Logistic Regression-
>>> from sklearn.datasets import load_iris
>>> from sklearn.linear_model import LogisticRegression
>>> X, y = load_iris(return_X_y=True)
>>> clf = LogisticRegression(random_state=0).fit(X, y)
>>> clf.predict(X[:2, :])
array([0, 0])
>>> clf.predict_proba(X[:2, :])
array([[9.8...e-01, 1.8...e-02, 1.4...e-08],
[9.7...e-01, 2.8...e-02, ...e-08]])
>>> clf.score(X, y)
0.97...2. Decision Tree – An artificial decision-making tree!

Decision Trees are probably one of the most useful supervised learning algorithms out there.
It is a machine learning algorithm that divides data sets into smaller data groups based on a descriptive feature until they reach sets that are small enough to be described by some label.
They require that you have data that is labeled (tagged with one or more labels, like the animal name in pictures of animals); they try to label new data based on that knowledge.
Unlike logistic regression, decision tree algorithms are perfect to solve classification as well as regression problems.
Decision Trees are composed of nodes, branches, and leaves.
Each node represents an attribute (or feature), each branch represents a rule (or decision), and each leaf represents an outcome. The depth of a tree is the number of levels, not including the root node.
A simple implementation of Decision Tree-
>>> from sklearn.datasets import load_iris
>>> from sklearn import tree
>>> iris = load_iris()
>>> X, y = iris.data, iris.target
>>> clf = tree.DecisionTreeClassifier()
>>> clf = clf.fit(X, y)
tree.plot_tree(clf) The tree.plot_tree() function outputs a tree graph. A tree can is a piece wise constant approximation.
3. Naive Bayes – Naive but Nice!
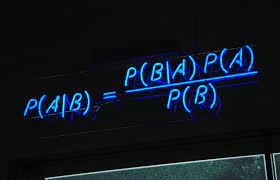
Now, if you remember basic probability, you know that in Bayes theorem we assume we have prior knowledge of any event that is related to the former event.
In a nutshell, Bayes tells us “Probability of X given Y“, and in mathematical terms, P(X|Y).
For example, to check the probability that you will be COVID positive, one would like to know if you face any symptoms of the disease.
However, the Naive Bayes classifier algorithm assumes that two events are independent of each other. This simplifies the calculations to a large extent.
Naive Bayes has shown that it works remarkably well in the real world as well.
A naive Bayes algorithm can be used to find simple relationships between different parameters without having complete data.
A simple implementation of Naive Bayes –
>>> from sklearn.datasets import load_iris
>>> from sklearn.model_selection import train_test_split
>>> from sklearn.naive_bayes import GaussianNB
>>> X, y = load_iris(return_X_y=True)
>>> X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, random_state=0)
>>> gnb = GaussianNB()
>>> y_pred = gnb.fit(X_train, y_train).predict(X_test)
>>> print("Number of mislabeled points out of a total %d points : %d"
... % (X_test.shape[0], (y_test != y_pred).sum()))
Number of mislabeled points out of a total 75 points : 4There are many variants of Naive Bayes and the above code shows implementation of Gaussian Naive Bayes.
The variants include Multinomial Naive Bayes, Complement Naive Bayes, Bernoulli Naive Bayes.
4. XGBoost – The Xtremes of Gradient Boosting!

Gradient boosting is based on the sequential and symbol learning model.
The base learners are generated sequentially so that the present-based learner is always more effective than the previous one. The overall model improves sequentially with each iteration now.
This happens to reduce loss function. The main idea here is to overcome the errors in the previous learner’s prediction.
Gradient Boosting has three main components–
- The loss function- which we optimize to reduce the error.
- Weak Learner – Decision trees are used as the weak learner in gradient boosting. This is to ensure that the learners remain weak, but can still be constructed in a greedy manner.
- Additive Model- Trees are added one at a time, and existing trees in the model are not changed. A gradient descent procedure is used to minimize the loss when adding trees.
XGBoost is an advanced version of gradient boosting.
It means extreme gradient boosting.
XGBoost is a more advanced version of the gradient boosting method. The main aim of this algorithm is to increase speed and to increase the efficiency of your competitions.
A simple implementation of XGBoost –
from sklearn import datasets
X,y = datasets.load_diabetes(return_X_y=True)
from xgboost import XGBRegressor
from sklearn.model_selection import cross_val_score
scores = cross_val_score(XGBRegressor(objective='reg:squarederror'), X, y, scoring='neg_mean_squared_error')
(-scores)**0.5This was the last Important Machine Learning Algorithms for Beginners
Conclusion
The best roadway for machine learning beginners is in practice and knowledge.
The more you understand what is the abstract role of each layer, the mechanics behind each function, the limitations, the easiest it will be to create a model faster. Hope you had fun reading this article!
This concludes the topic of important Machine Learning Algorithms for Beginners!
Loved this?
Contact us for more such articles!
